Apache Camel, Kamelets y Kafka: Transformando la Integración de Datos
![]()
Apache Camel
Apache Camel es un proyecto de código abierto basado en EIP (Enterprise Integration Patterns) que proporciona una plataforma para definir y ejecutar rutas de integración entre sistemas. Dispone de un catálogo de más de 300 conectores tanto de entrada (source) como de salida (sink) que permiten la interacción y el manejo de datos entre diferentes sistemas.
Está basado en rutas, las cuales se pueden enlazar unas con otras para realizar transformaciones, filtrados y volcados en diferentes sistemas con sus diferentes formatos.
La potencia de Apache Camel ha sido fruto del trabajo de la Apache Software Foundation desde 2007, adaptando la manera de codificar las rutas y llegando a proveer un DSL (Domain Specific Language) en diferentes lenguajes (Java, XML, Kotlin...).
Integrando Datos con Apache Camel
Es recurrente encontrar datos de clientes dispersos entre sistemas y en diferentes formatos. Imagina una empresa de mensajería que recopila datos de ubicación en tiempo real de sus vehículos a través de sistemas GPS. Estos datos deben integrarse con el sistema de gestión de rutas para optimizar las rutas y con el sistema de gestión de clientes para enviar actualizaciones sobre la entrega.
Apache Camel encaja de forma ideal en este escenario. Actúa como un puente entre los sistemas de seguimiento GPS y los sistemas internos de la empresa. Desde la captura inicial de la ubicación hasta la generación de actualizaciones automatizadas para los clientes, Apache Camel garantiza una integración de forma sencilla, actuando como el enlace entre estas aplicaciones, conectando todo de manera ordenada.

Pero aquí no termina la cosa. Piensa en un caso más concreto: gestionar las transacciones de una tienda online. Cada compra genera datos críticos y de gran valor que necesitan ser validados, enriquecidos con detalles adicionales (como el historial de compras del cliente), y registrados en el sistema de gestión de inventario. Apache Camel puede suscribirse al flujo de datos generado por Apache Kafka, realizar todas estas operaciones de transformación y enriquecimiento, y asegurarse de que la información llegue a donde debe llegar, sin errores y en tiempo real.
¿Camel o Kafka? Mejor juntos
En el mundo de la integración de datos, muchas veces surge la típica pregunta: ¿es mejor elegir Apache Camel o Apache Kafka? La verdad es que no se trata de elegir uno y descartar el otro, sino de saber cómo combinarlos para sacar lo mejor de cada uno.
Apache Camel es una herramienta muy útil que te permite integrar distintos sistemas mediante un catálogo amplísimo de componentes. Es perfecta para transformar, enrutar y mediar entre diferentes fuentes y destinos de datos. Su flexibilidad y capacidad de extensión lo hacen ideal para prácticamente cualquier escenario de integración.
Por otro lado, Apache Kafka es una plataforma de streaming de eventos, diseñada para manejar grandes volúmenes de datos en tiempo real.
En lugar de ver a Camel y Kafka como opciones mutuamente excluyentes, piensa en cómo pueden trabajar juntos. Aquí hay algunas situaciones donde combinan perfectamente:
-
Transformación y Enrutamiento de Datos: Utiliza Apache Camel para transformar y enrutar datos antes de publicarlos en un topic de Kafka. Esto es especialmente útil cuando necesitas normalizar datos de diferentes fuentes antes de procesarlos.
-
Procesamiento en Tiempo Real: Apache Kafka puede manejar el flujo continuo de datos en tiempo real, mientras que Camel puede consumir esos datos, procesarlos y luego enviarlos a otros sistemas o bases de datos.
-
Integración Híbrida: Si tu infraestructura incluye sistemas que no están directamente soportados por Kafka, Apache Camel puede actuar como el conector que integra esos sistemas con tu pipeline de Kafka.

Entonces, continuando con el ejemplo de una tienda online en el que quieres enriquecer el procesamiento de las transacciones de compra recolectando datos sobre cómo interactúan los clientes en redes sociales y otros canales, Apache Camel es un intermediario ideal. Imagina que la tienda captura todo, desde publicaciones en redes como Facebook o Twitter hasta chats en línea y correos electrónicos. Cada fuente tiene su propio formato y estructura de datos, lo cual complica la integración.
Apache Camel facilita esta integración actuando como el puente entre todos estos sistemas externos y Kafka. Antes de que los datos lleguen a Kafka para su procesamiento, Camel se encarga de normalizar los esquemas de datos, limpiar inconsistencias, agrupar información dispersa y aplicar reglas de negocio necesarias. Todo esto asegura que los datos sean consistentes cuando vayan a ser consumidos por clientes Kafka.
La implementación de esta solución es un desafio si se recurre solo a, por ejemplo, Kafka Streams, que está más centrada en el análisis y procesamiento en tiempo real de datos dentro del ecosistema de Kafka. Así que, gracias a Apache Camel, la tienda puede gestionar esta mezcla de datos y prepararlos para su análisis.
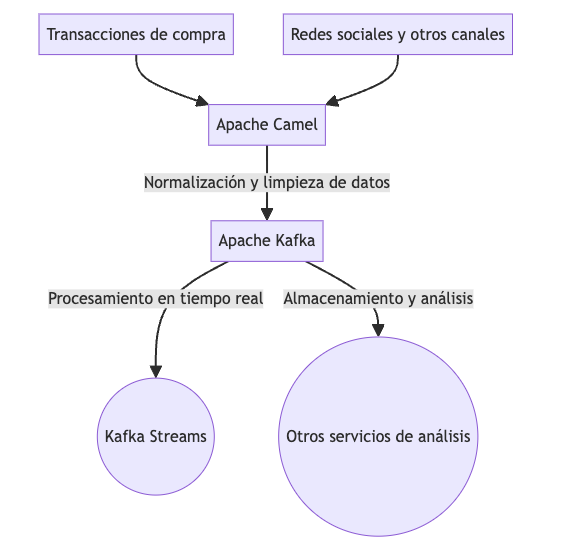
No se trata de elegir entre Apache Camel y Apache Kafka, sino de entender cómo pueden complementarse. Cada uno aporta fortalezas únicas que, cuando se combinan, ofrecen una solución de integración de datos robusta, flexible y eficiente. Así que la próxima vez que te enfrentes a una integración de este tipo, valora usar ambos.
KafkaRoute.java define rutas en Apache Camel para procesar y normalizar transacciones de compra desde Kafka y datos de redes sociales obtenidos mediante una API REST, enviándolos luego a otro topic de Kafka.
package com.example.demo.routes;
import org.apache.camel.builder.RouteBuilder;
import org.bson.Document;
import org.springframework.stereotype.Component;
@Component
public class KafkaRoute extends RouteBuilder {
@Override
public void configure() throws Exception {
// Route for processing purchase transactions
from("kafka:purchase-transactions?brokers=localhost:9092")
.process(exchange -> {
String message = exchange.getIn().getBody(String.class);
Document doc = new Document();
doc.put("type", "purchase");
doc.put("message", message);
exchange.getIn().setBody(doc);
})
.to("direct:normalize");
// Route for processing social media and other channels via REST API
from("timer://fetchSocialMedia?period=60000") // Fetch every minute
.to("rest:get:api/social-media")
.process(exchange -> {
String message = exchange.getIn().getBody(String.class);
Document doc = new Document();
doc.put("type", "social");
doc.put("message", message);
exchange.getIn().setBody(doc);
})
.to("direct:normalize");
// Normalization and cleaning route
from("direct:normalize")
.process(exchange -> {
Document doc = exchange.getIn().getBody(Document.class);
// Normalization and cleaning logic here
// e.g., removing null values, ensuring schema consistency, etc.
exchange.getIn().setBody(doc.toJson());
})
.to("kafka:normalized-data?brokers=localhost:9092");
}
}
La clase KafkaRoute define rutas de Apache Camel para:
- Procesar transacciones de compra desde un topic de Kafka.
- Obtener y procesar datos de redes sociales y otros canales a través de una API REST.
- Normalizar y limpiar los datos antes de enviarlos a otro topic de Kafka.
Como podemos ver, se le especifican los siguientes parámetros:
- From: Define de dónde queremos leer los datos.
- Process: Convierte los mensajes a documentos.
- To: Especifica el canal de salida.
Apache Camel K
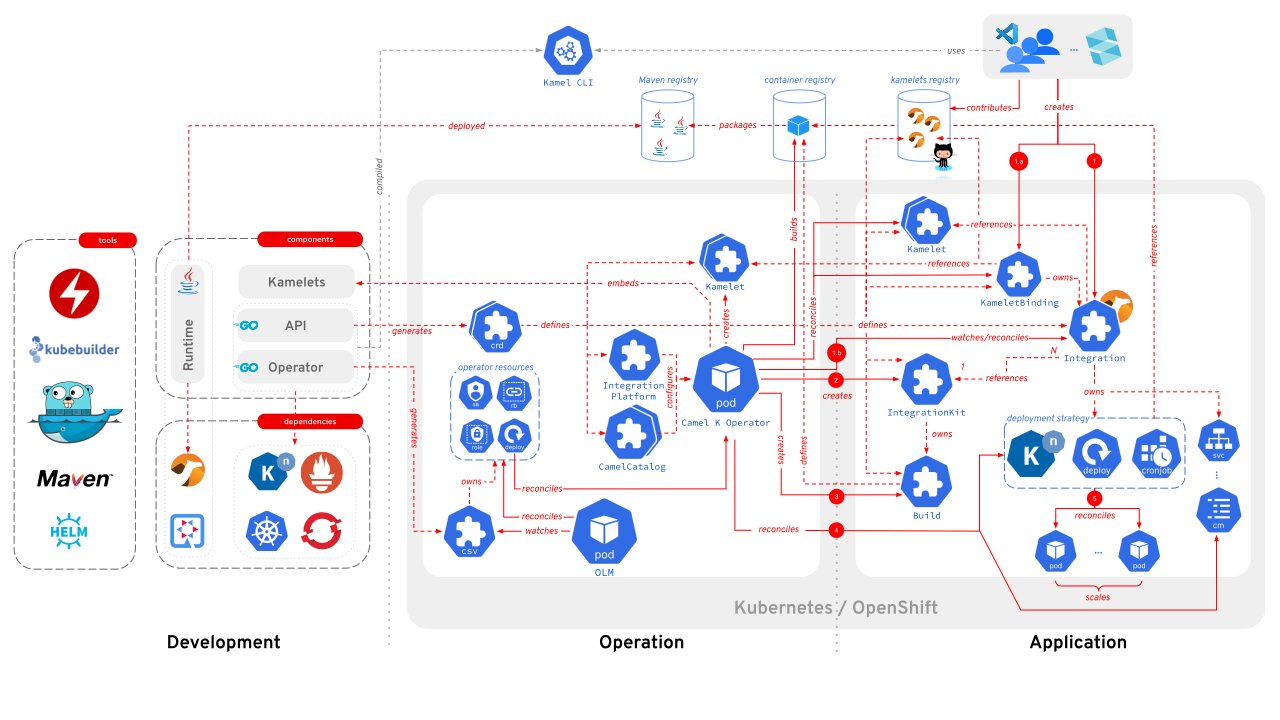
Apache Camel ha evolucionado a lo largo de los años y una de sus variantes es Apache Camel K, diseñada específicamente para trabajar en entornos Kubernetes y serverless. Su principal objetivo es simplificar la integración de sistemas en la nube, permitiendo que las rutas de Camel se ejecuten como microservicios nativos en Kubernetes sin la necesidad de un servidor de aplicaciones tradicional.
Kubernetes se encarga de gestionar las integraciones con la ayuda de un operador (kamelk operator)y algunas reglas personalizadas (CRDs) que el operador entenderá para trabajar con Kubernetes y crear lo que se necesita.
Utilizando Kamel CLI se establece comunicación con el operador de Camel, que configura el proyecto, cataloga el código, abstrae partes complejas, resultando en una imagen docker. El operador despliega esa imagen, automatizando tareas relacionadas con infraestructura y configuración de la aplicación.
Esta combinación de Camel y Kubernetes simplifica mucho el proceso de desarrollo y despliegue. Camel K y su operador hacen la mayor parte del trabajo pesado.
Entre sus características principales podemos establecer las siguientes:
-
Optimizado para Kubernetes: Camel K está diseñado para aprovechar las características de Kubernetes, permitiendo despliegues rápidos y escalabilidad automática.
-
Desarrollo rápido: Reduce el ciclo de desarrollo al permitir que los desarrolladores escriban rutas de integración directamente en su lenguaje preferido y las desplieguen en Kubernetes con un solo comando.
-
Integración con Knative: Camel K se integra perfectamente con Knative, lo que facilita la creación de flujos de trabajo serverless y la ejecución de integraciones en respuesta a eventos.
-
Ligero: Al no requerir un servidor de aplicaciones y al optimizar las rutas para la ejecución en contenedores, Camel K es ligero y eficiente en términos de recursos.
-
Soporte para múltiples lenguajes: Aunque Camel tradicionalmente ha sido asociado con Java, Camel K soporta múltiples lenguajes DSL, incluyendo Java, XML, YAML, Kotlin y Groovy.
Aparte del Kamel CLI, para realizar la instalación de Apache Camel K existen varios sabores de operador en función de nuestras necesidades:
Una vez instalado, podemos crear un fichero KafkaToMongoRoute.java similar al del ejemplo anterior y desplegarlo en nuestro cluster con el siguiente comando:
kamel run KafkaRoute.java
En este punto nuestra ruta de integración con Apache Camel K estaría desplegada y disponible como un pod en nuestro cluster de kubernetes.
NAME READY STATUS RESTARTS AGE
kafkaroute-1-deploy 0/1 Pending 0 5s
Apache Camel Kamelets
Los Kamelets permiten aprovechar la potencia de Camel K sin necesidad de conocerlo a fondo. Son fragmentos de código que facilitan la conexión con otros sistemas sin tener que preocuparse por los detalles técnicos.
Los Kamelets ofrecen varias ventajas significativas en la integración de servicios en Kubernetes. Simplifican y agilizan este proceso al proporcionar una abstracción sobre Apache Camel, permitiendo su uso sin necesidad de ser un experto en Camel. Además, facilitan la conexión con aplicaciones basadas en eventos como Apache Kafka y Knative, pudiendo convertirse en una ventaja significativa en ecosistemas de microservicios. Además, promueven la reutilización de código al estar basados en plantillas predefinidas.
Tipos de Kamelets
Los Kamelets se dividen en tres tipos:
- Source: Leen datos de sistemas externos.
- Sink: Envían datos a sistemas externos o realizan alguna acción con dichos datos.
- Action: Hacen una tarea intermedia, como convertir un evento en un archivo PDF antes de enviarlo a un sink.
Se puede utilizar un Source o un Sink para escuchar o disparar diferentes tipos de eventos. Por ejemplo, puedes conectar un canal Kafka directamente a un broker JMS o cola SQS utilizando Kamelets.
Por otra parte, un Kamelet Pipe te permite decirle a un Kamelet source que envíe eventos a un destino que puede ser representado por un canal Knative, un topic Kafka o una URI genérica. El mismo mecanismo permite que un Kamelet Sink consuma eventos. De esta manera, los Kamelet Bindings definen cómo fluyen los eventos en una arquitectura orientada a eventos. La lógica de enrutamiento está completamente abstraída por los componentes Camel.
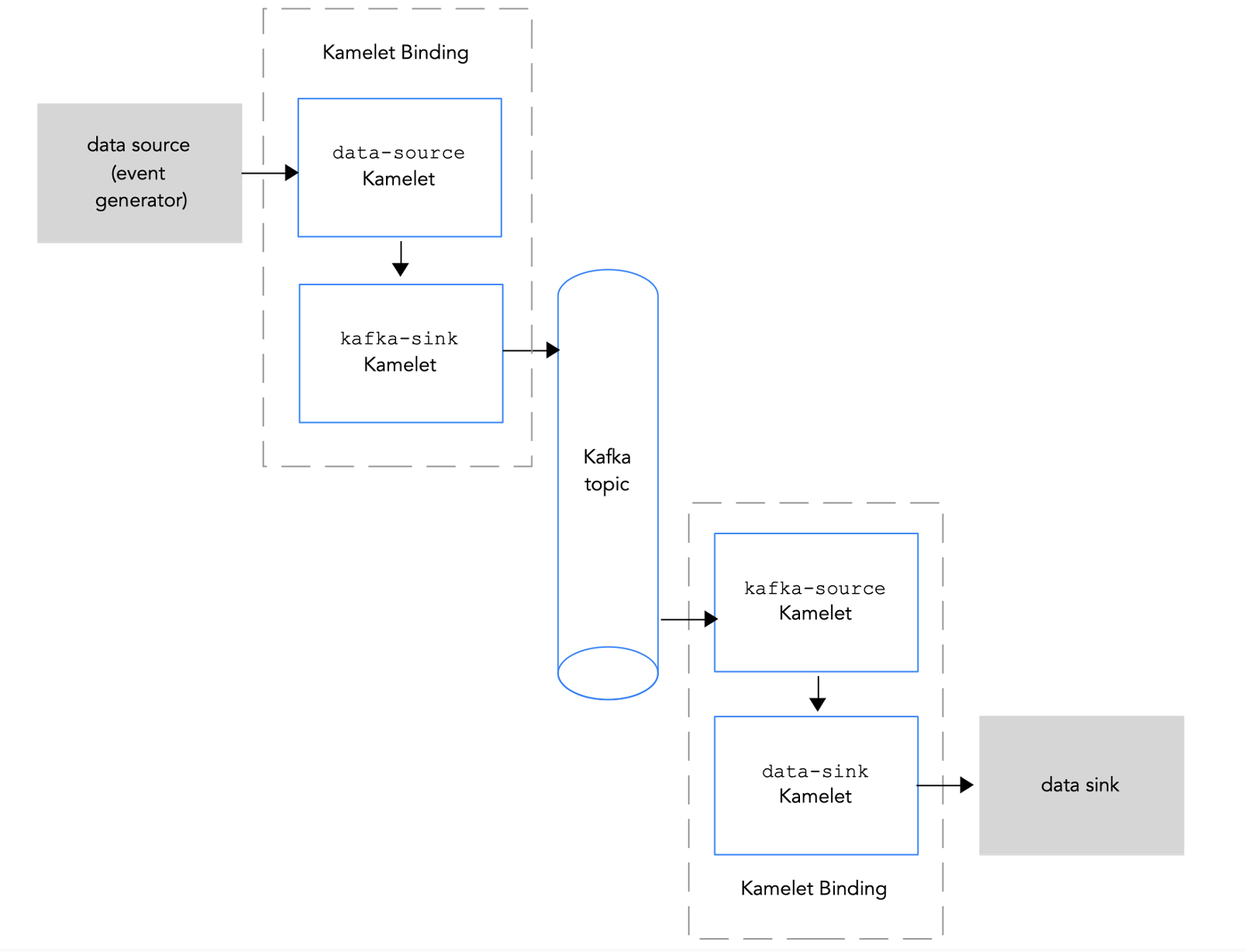
Kamelet Pipe
En este ejemplo de código con Kamelets de Apache Camel, montamos un Pipe para conectar Kafka con una cola SQS de AWS.
En el lado del source (fuente), usamos el Kamelet kafka-source para consumir datos del topic my-source-topic en Kafka.
Por otro lado, en el sink (destino), tenemos el Kamelet aws-sqs-sink. Aquí ponemos las credenciales como accessKey y secretKey, además de especificar la región eu-west-1 donde se encuentra la cola y el nombre o ARN de la misma en queueNameOrArn.
apiVersion: camel.apache.org/v1
kind: Pipe
metadata:
name: kafka-sink
spec:
source:
ref:
kind: Kamelet
apiVersion: camel.apache.org/v1
name: kafka-source
properties:
topic: my-source-topic
bootstrapServers: localhost:9092
password: pwd
user: user
sink:
ref:
kind: Kamelet
apiVersion: camel.apache.org/v1alpha1
name: aws-sqs-sink
properties:
accessKey: "The Access Key"
queueNameOrArn: "The Queue Name"
region: "eu-west-1"
secretKey: "The Secret Key"
Extensibilidad con Kamelets: Añadiendo un Parámetro Personalizado
Supongamos que queremos añadir un parámetro personalizado a kafka-source para filtrar los mensajes que contienen una palabra clave específica antes de enviarlos al sink.
apiVersion: camel.apache.org/v1
kind: Kamelet
metadata:
name: kafka-source
spec:
definition:
title: "Kafka Source"
description: "Consume messages from a Kafka topic with optional filtering"
required:
- topic
- brokers
properties:
topic:
title: Kafka Topic
description: The Kafka topic to consume messages from.
type: string
brokers:
title: Kafka Brokers
description: A comma-separated list of Kafka brokers.
type: string
keyword:
title: Filter Keyword
description: A keyword to filter messages.
type: string
default: ""
template:
from:
uri: "kafka:{{topic}}?brokers={{brokers}}"
steps:
- choice:
when:
simple: "{{keyword}} == '' || body.contains('{{keyword}}')"
steps:
- to: "kamelet:sink"
Con esta extensión, puedes filtrar mensajes por una palabra clave antes de enviarlos al sink. Simplemente añade el nuevo parámetro keyword en el Kamelet Pipe:
apiVersion: camel.apache.org/v1
kind: Pipe
metadata:
name: kafka-sink
spec:
source:
ref:
kind: Kamelet
apiVersion: camel.apache.org/v1
name: kafka-source
properties:
topic: my-source-topic
bootstrapServers: localhost:9092
password: pwd
user: user
keyword: important
sink:
ref:
kind: Kamelet
apiVersion: camel.apache.org/v1
name: kafka-sink
properties:
topic: my-sink-topic
bootstrapServers: localhost:9092
password: pwd
user: user
¿Apache Camel Kamelets o Kafka Connect?
Si ahora estás dudando entre Apache Camel Kamelets y Kafka Connect para tus integraciones en Kafka, ambas son buenas opciones, aunque tienen diferencias significativas en su enfoque y funcionalidades.
Apache Camel Kamelets
Apache Camel Kamelets simplifica la integración de sistemas en entornos Kubernetes al ofrecer una amplia gama de conectores listos para usar. Es como tener un kit de herramientas que te permite conectar sistemas externos de manera rápida.
Ventajas y Desventajas
| Ventajas | Desventajas |
|---|---|
| Extenso catálogo de conectores | Curva de aprendizaje inicial |
| Basado en Quarkus | Menos especialización en Kafka |
| Permite añadir parámetros personalizados | Configuraciones más simples que Kafka Connect |
| Resiliencia, escalado, observabilidad basada en k8s | Requiere infraestructura k8s |
| Amplio catálogo de componentes |
Kafka Connect
Kafka Connect, por otro lado, está diseñado específicamente para integrarse con Apache Kafka y mover datos dentro y fuera de su contexto. Ofrece conectores preconstruidos para una variedad de sistemas, pero dirigido especificamente para el ecosistema Kafka.
El término medio se encuentra en los conectores Camel Kafka Connect, que como su propia documentación dice, se trata de adaptadores para Kafka Connect de Apache Camel para conseguir una forma amigable de usar Apache Camel en el ecosistema Kafka. Adolece de algunas desventajas de Kafka Connect y Camel, pero añade tipos de integración que no se encuentran en su catálogo (en la actualidad 172 conectores).
Ventajas y Desventajas
| Ventajas | Desventajas |
|---|---|
| Especialización en integraciones con Apache Kafka | Menos flexible fuera del ecosistema de Kafka |
| Conectores preconstruidos para diferentes sistemas | Configuración más compleja para personalizaciones |
| Escalabilidad horizontal para grandes volúmenes de datos | |
| Configuración declarativa clara y simple |
Elección entre Apache Camel Kamelets y Kafka Connect
-
Si necesitas una amplia variedad de conectores para diferentes sistemas: Apache Camel Kamelets ofrece un catálogo más extenso y flexible que Kafka Connect, lo que facilita integraciones más generales fuera del ecosistema de Kafka.
-
Si estás trabajando principalmente con Apache Kafka y necesitas una especialización en integraciones específicas: Kafka Connect proporciona conectores optimizados y una configuración declarativa que es ideal para integraciones dentro del ecosistema de Kafka.
Ambas opciones pueden complementarse dependiendo del caso de uso, permitiéndote utilizar Apache Camel Kamelets para integraciones más generales y Kafka Connect para integraciones específicas con Apache Kafka.