Inteligencia artificial en Elasticsearch: Haciendo las búsquedas más inteligentes
A pesar de no ser un concepto nuevo, desde finales de 2022 con la llegada de ChatGPT, la inteligencia artificial se ha convertido en protagonista principal de nuestras vidas y, como era de esperar, también ha cobrado importancia en la hoja de ruta de cualquier producto. Cada vez son más los dispositivos y aplicaciones que utilizamos a diario que incorporan ese nuevo botoncito tan molón que nos permite utilizar la IA para generar texto, imágenes, vídeos o identificar patrones de comportamiento. Y es que la IA generativa está cambiando nuestra forma de interactuar con las máquinas.
Elasticsearch no es ajeno a esta evolución, y en sus últimas versiones ha ido liberando nuevas funcionalidades que permiten aplicar distintas técnicas y modelos de machine learning e inteligencia artificial dentro de nuestro propio clúster, extrayendo información valiosa de nuestros documentos almacenados, mejorando la experiencia de búsqueda y sobre todo, abriendo un gran abanico de soluciones y casos de uso que se pueden implementar de forma sencilla.
¿Cómo está integrando Elastisearch la inteligencia artificial?
Elastic ha lanzado ESRE (Elasticsearch Relevance Engine™), un conjunto de herramientas creadas para impulsar el desarrollo de aplicaciones de búsquedas basadas en inteligencia artificial. Permite integraciones con LLM (Large Language Model), hacer inferencias con modelos IA, búsquedas vectoriales...
Condensar todo lo que ofrece ESRE en un solo post es complicado, por lo que intentaremos centrarnos en dos de las funcionalidades que más nos han llamado la atención:
- Usar modelos de inteligencia artificial ya entrenados para hacer inferencias sobre los datos del clúster en tiempo real.
- Revolucionar el mundo de la búsqueda tradicional haciéndola más inteligentes.
Vamos a ver los detalles de qué nos aportan cada una de estas mejoras.
Uso de modelos IA en Elasticsearch
Elastic ahora permite cargar y ejecutar modelos de IA dentro del propio clúster, independientemente de si han sido desarrollados y entrenados con el dominio de tu compañía, o es un modelo ya entrenado de terceros disponibles en un repositorio público como HuggingFace.
Estos modelos son alojados en el propio clúster y permiten ser ejecutados realizando inferencias sobre cada documento que sea indexado en un índice, pudiendo realizar tareas de procesamiento de lenguaje natural (NLP), reconocimiento de entidades (NER), clasificación de texto, text embedding, análisis de sentimientos...
A continuación veremos cómo podemos utilizar uno de estos modelos.
Importación del modelo
Para importar estos modelos dentro de Elastic, se utiliza Eland, un cliente Python de Elastic que ofrece librerías que permiten trabajar con los datos alojados en el clúster con una API compatible con librería pandas, y que ofrece la posibilidad de cargar modelos IA desde fuentes externas.
Para el ejemplo, hemos elegido este modelo de reconocimiento de entidades (NER) disponible en HuggingFace que permite extraer entidades desde un texto no estructurado. Vamos a cargarlo en nuestro clúster a través de Eland, indicando la URL de Elastic y el tipo de tarea a realizar ("ner" en el caso del ejemplo):
eland_import_hub_model --url http://my-elasticsearch-clúster --hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english --task-type ner
El propio comando nos indica que el modelo ha sido cargado satisfactoriamente en Elastic.
2024-06-05 09:10:06,429 INFO : Establishing connection to Elasticsearch
2024-06-05 09:10:06,472 INFO : Connected to clúster named 'elasticsearch' (version: 8.13.4)
2024-06-05 09:10:06,476 INFO : Loading HuggingFace transformer tokenizer and model 'elastic/distilbert-base-uncased-finetuned-conll03-english'
tokenizer_config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 258/258 [00:00<00:00, 399kB/s]
config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 904/904 [00:00<00:00, 1.52MB/s]
vocab.txt: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 232k/232k [00:00<00:00, 1.18MB/s]
special_tokens_map.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 112/112 [00:00<00:00, 220kB/s]
model.safetensors: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 265M/265M [00:07<00:00, 33.4MB/s]
2024-06-05 09:10:20,296 INFO : Creating model with id 'elastic__distilbert-base-uncased-finetuned-conll03-english'
2024-06-05 09:10:20,460 INFO : Uploading model definition
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 64/64 [00:10<00:00, 5.98 parts/s]
2024-06-05 09:10:31,157 INFO : Uploading model vocabulary
2024-06-05 09:10:31,255 INFO : Model successfully imported with id 'elastic__distilbert-base-uncased-finetuned-conll03-english'
Desde la propia interfaz de Kibana podemos interactuar con el modelo cargado, comprobar sus detalles, configuración, iniciarlo, probar a hacer inferencias para ver cómo funciona y hasta decidir los recursos que va a utilizar.
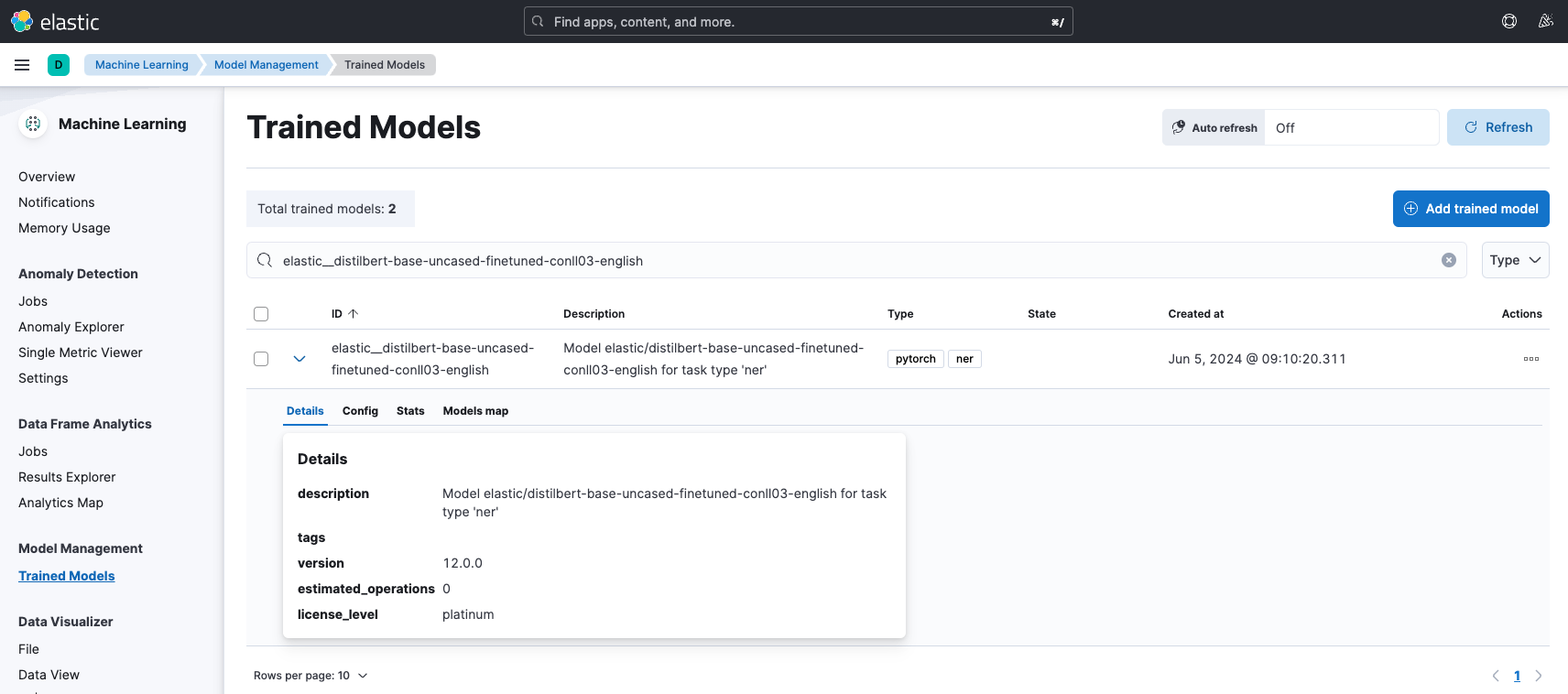
Uso del modelo para hacer inferencias
Una vez iniciado, el modelo estaría disponible para hacer inferencias. Para ello, se ha creado el API Machine Learning trained models, que permite la interacción con estos modelos.
Mediante el endpoint _infer podemos probar el modelo haciendo una inferencia con un texto que contenga entidades como nombres, ciudades o empresas. Por ejemplo, probamos a hacer una inferencia con el texto "My name is Juan, I live in Madrid and I work at Mimacom":
POST /_ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/_infer
{
"docs": {
"text_field": "My name is Juan, I live in Madrid and I work at Mimacom"
}
}
El modelo desplegado extrae las entidades del texto y las categoriza por tipo, detectando que "Juan" es una persona, "Madrid" una localización y "Mimacom" una organización. Esta es la repuesta a la inferencia que acabamos de realizar:
{
"inference_results": [
{
"predicted_values": "My names is [Juan](PER&Juan), I live in [Madrid](LOC&Madrid) and I work at [Mimacom](ORG&Mimacom)",
"entities": [
{
"entity": "Juan",
"class_name": "PER",
"class_probability": 0.99419412467215481,
"start_pos": 11,
"end_pos": 15
},
{
"entity": "Madrid",
"class_name": "LOC",
"class_probability": 0.9987014189632654,
"start_pos": 27,
"end_pos": 33
},
{
"entity": "Mimacom",
"class_name": "ORG",
"class_probability": 0.994548109621911,
"start_pos": 48,
"end_pos": 55
}
]
}
]
}
Independiemente del modelo que se utilice, el resultado de estas inferencias queda almacenado en cada documento, por lo que puede ser utilizado para construir paneles que muestren el resultado de la ejecución de estos modelos. Con este ejemplo de reconocimiento de entidades podemos construir un panel que muestre en tiempo real información agregada sobre personas, organizaciones o localizaciones extraída de información desestructurada y sin la necesidad de tratarla previamente.
Además de la API, también se ha desarrollado el Inference processor para poder utilizar estos modelos en una pipeline de ingesta de Elasticsearch y así poder realizar estas inferencias de forma automática contra cualquier documento que llegue al clúster directamente en el momento en el que se ingesta.
Hay una gran cantidad de modelos disponibles que pueden ser importados en Elastic y utilizados para realizar inferencias sobre los datos almacenados en el clúster. Esto nos permite implementar casos de uso como obtener una categorización automática de texto (por ejemplo por nivel de urgencia) o detectar automáticamente el sentimiento que genera un texto (para poder hacer valoraciones sobre los comentarios de tus productos), realizar búsquedas vectoriales...
Aunque a día de hoy (v8.14) está en technical preview, Elasticsearch está trabajando en evolucionar este proceso de cargar y usar modelos, y ha desarrollado un nuevo Infer API que permite realizar inferencias utilizando servicios alojados en otros sistemas distintos a Elastic. Actualmente, soporta integraciones con servicios ejecutados en:
- Cohere
- Hugging Face
- OpenAI
- Azure OpenAI
Esta API permite la integración con servicios de LLM (Large Language Model) con un alto nivel de entrenamiento y ya contrastados en el mercado.
Revolución del mundo de la búsqueda tradicional mediante IA
"You know, for search! ", la frase más famosa de Elastic nos recuerda que nació siendo un buscador. El objetivo de un buscador es ofrecer de forma concisa y rápida los resultados que el usuario está tratando de encontrar; y, tradicionalmente, han funcionado buscando coincidencias de palabras claves, evolucionando con el paso del tiempo para soportar sinónimos, analizadores personalizados, fuzzy search...
ESRE ofrece capacidades de inteligencia artificial que transforman el funcionamiento de las búsquedas tradicionales, permitiendo nuevos tipos de búsquedas más avanzadas que veremos a continuación, como búsquedas semánticas, híbridas o técnicas RAG (retrieval augmented generation).
Búsquedas semánticas
Una búsqueda semántica no busca coincidencias entre palabras, sino que, apoyándose en técnicas de procesamiento de lenguaje natural, comprende el contexto, la relación entre las palabras, la intención del usuario o la polisemia, es decir, sabe diferenciar entre la palabra "Apple" como fruta o "Apple" como compañía por el contexto de la frase en el que se encuentra, devolviendo un resultado u otro dependiendo del significado por el que el usuario está buscando.
Para conseguir estas búsquedas semánticas, se utilizan vectores de búsqueda, es decir, el texto se convierte en una representación de vectores numéricos (text embeddings) al igual que el texto que se está buscando. Esto permite comparar ambos vectores y así poder calcular la similitud entre ellos (score) por su significado y no por palabras clave.
Elasticsearch soporta estos vectores numéricos con los nuevos tipos de datos dense_vector y sparse_vector, creados para almacenarlos. Como hemos visto anteriormente, también permitía la carga de modelos de text embeddings que permitían convertir texto en vectores numéricos, por lo que es sencillo cargar un modelo de text embedding y convertir documentos en su representación vectorial para luego poder realizar estas búsquedas.
Pero la gran novedad llega con ELSER (Elastic Learned Sparse EncodeR), un modelo de machine learning desarrollado y entrenado por Elastic que permite realizar búsquedas semánticas sin tener que cargar un modelo externo, crear uno nuevo o tener que hacer un "fine-tuning" de alguno existente.
Este modelo también utiliza un nuevo tipo de búsqueda semántica, llamada text_expansion, que está disponible out of the box en Elastic, listo para ser desplegado y utilizado a través de la interfaz de Kibana. Su uso está recomendado para texto en inglés, para multilenguaje por defecto también está incluido el modelo E5. Este modelo permite realizar búsquedas semánticas de forma sencilla en Elasticsearch, abriendo un nuevo caso de uso que permite a los usuarios no tener que buscar expresamente por una palabra clave, sino realizar la consulta utilizando lenguaje natural. Ya no es necesario que las palabras utilizadas al buscar aparezcan en los resultados. Esto orienta las consultas más a una conversación que a una simple búsqueda por términos.
Búsquedas híbridas
Las ventajas de las búsquedas vectoriales pueden hacernos pensar que la búsqueda tradicional de Elasticsearch y su famoso índice invertido dejarán de ser utilizadas, pero existen muchos casos en los que una búsqueda tradicional (full text) es más efectiva, por ejemplo si queremos aplicar un simple filtro por categoría o buscar documentos que contengan un término en algún campo.
Pero... ¿y si pudiésemos utilizar las dos a la vez en una misma consulta? Para ello, Elastic ha creado las búsquedas híbridas, que permiten aplicar una estrategia que combina varios métodos de búsqueda (vectorial o full text) en una misma consulta, aprovechando las ventajas de ambas para obtener los mejores resultados.
Cada consulta es ejecutada y gracias a un algoritmo llamado Reciprocal Rank Fusion (RRF), la lista de los resultados devueltos por cada estrategia de búsqueda es combinada en un solo listado de resultados de forma inteligente, mejorando la experiencia de búsqueda del usuario de forma notable.
Técnicas RAG (retrieval augmented generation)
Con el auge de los LLM como GPT, Gemini, Gemma, Llama... cada vez existen más aplicaciones que utilizan las API de estos modelos para realizar preguntas y mantener conversaciones. Una de las claves para que estos modelos sean capaces de generar texto y responder estas preguntas es la gran cantidad de datos con los que han sido entrenados.
Hay compañías que intentan desarrollar y entrenar modelos con los datos de su propio dominio, esto hace que las respuestas del LLM sean más certeras, estén más actualizadas y siempre tengan el contexto adecuado de los usuarios que buscan información. El problema es que desarrollar y entrenar estos modelos con tus propios datos de forma sofisticada y continua es algo que requiere de mucho tiempo, conocimiento y recursos.
RAG intenta buscar una alternativa a este problema. Esta técnica consiste en capturar la pregunta que el usuario hace al LLM (prompt), buscar la información más relevante sobre esa consulta entre los datos de la propia compañía (proceso de retrieval) y enviar al LLM la pregunta original del usuario acompañada de toda la información de negocio valiosa recuperada de los datos privados de la compañía (contexto). De esta forma, el LLM recibe la pregunta del usuario acompañada de ese contexto, que le ayudará a desarrollar una respuesta mucho más acertada.
Por ejemplo, un usuario puede preguntar a un LLM "¿cómo puedo solicitar una devolución?", y la respuesta dependerá de lo que el LLM entienda por devolución, que probablemente sea información general sobre cómo se realiza normalmente una devolución o incluso responder con una alucinación. Con RAG, se realizaría una búsqueda entre los datos de la organización y se obtendría la información en la que se explica el proceso de devoluciones de la propia compañía, formas de devolución, períodos, lugares... tanto la pregunta original como todo el contexto recuperado se enviarían al LLM, que generará una respuesta con la información específica que el usuario ha buscado, añadiendo incluso referencias externas para respaldar la información, ofreciendo una experiencia de usuario mucho mejor sin tener que haber previamente entrenado el modelo.
Cuanto mejor sea el contexto, más precisa y personalizada será la respuesta, por lo que esa búsqueda cobra una importancia crítica.
ESRE sitúa a Elasticsearch como una solución para el desarrollo de aplicaciones de arquitectura RAG con poco esfuerzo, ya que puede implementar las principales características de las que consta la arquitectura RAG:
- Es capaz de almacenar grandes cantidades de información actualizada (por ejemplo, usando la solución de web crawler de la que dispone) y segmentarlas por permisos para restringir ciertos resultados de las búsquedas a usuarios autorizados.
- Puede realizar potentes búsquedas (vectoriales o híbridas) usando lenguaje natural entre los datos de la compañía de forma sencilla, lo que le permite generar resultados que ayudarán al modelo LLM a dar una mejor respuesta.
- Dispone de mecanismos para trabajar como base de datos vectorial e integrarse con LLM gracias a las plantillas y retrievers disponibles en LangChain.
Conclusión
La integración de la inteligencia artificial en Elasticsearch ha transformado la forma en que se realizan las búsquedas. La capacidad de realizar búsquedas semánticas eleva la experiencia de usuario, permitiéndole hacer consultas en lenguaje natural y ofreciendo resultados personalizados, más precisos y relevantes gracias a que comprende el contexto y significado de las consultas.
Elasticsearch es un buscador asentado en el mercado desde hace años, lo que hace que existan multitud de compañías o productos cuyos buscadores estén implementados con Elastic, como por ejemplo Liferay. Estos productos pueden aprovechar todo este potencial de búsquedas y mejorar la experiencia de sus usuarios, incorporando, sin mucho esfuerzo, funcionalidades... como búsquedas semánticas o integraciones con LLM.
Hay otra serie de hechos que nos demuestran la evolución de Elasticsearch en el ámbito de la inteligencia artificial, por ejemplo:
- Elasticsearch se ha convertido en una de las bases de datos vectorial más votadas por la comunidad LangChain.
- Al desplegar un clúster de Elasticsearch en cloud se puede elegir entre distintos perfiles de hardware en base al caso de uso que pretende resolver (propósito general, optimizado para búsquedas, para ingesta masiva...). Ahora existe una nueva opción para elegir un clúster optimizado para realizar búsquedas vectoriales, lo que demuestra que se ha convertido en un nuevo caso de uso.
- A partir de las últimas versiones, Kibana ofrece un asistente virtual con conectores para poder hacer preguntas a un LLM directamente.
- Han lanzado Search Labs, un nuevo portal con tutoriales y avanzados ejemplos en notebooks que permiten probar las distintas integraciones.
En resumen, Elasticsearch nació como un buscador en 2012 y fue ganando terreno como solución de observabilidad, seguridad o SIEM a lo largo de los años. Creemos que la adopción de la inteligencia artificial le va a permitir abordar muchos nuevos casos de uso y evolucionar los ya existentes de una manera rápida y sin la necesidad de tener un conocimiento amplio sobre aprendizaje automático.