Kafka Streams Metrics with Spring Boot
En este artículo voy a explicar cómo configurar las metricas out-of-the-box y custom de Kafka Streams usando Spring Boot y Spring-Kafka.
Introducción
Kafka Streams es una libreria java de procesamiento de flujo de datos continuo, como agregar, transformar o filtrar eventos. Permite a los desarrolladores crear aplicaciones de procesamiento en tiempo real. Kafka Streams usa Apache Kafka, con la que se integra perfectamente.
Podemos mencionar productos similares como Spark, Flink y Storm. Todos ellos tienen particularidades. En el caso de Kafka Streams funciona siempre con Apache Kafka como origen y destino de datos, es posible llevar estos datos a sistemas externos usando Kafka Connect. Para gestionar el estado Kafka Streams usa RocksDB, que es una base de datos embebida en la libreria. También proporciona tolerancia a fallos activo-pasivo, si uno de los microservicios que lo contiene falla.
Aquí puedes encontrar la pagina oficial de métricas para Confluent Kafka Streams: https://docs.confluent.io/platform/current/streams/monitoring.html
La aplicación de ejemplo
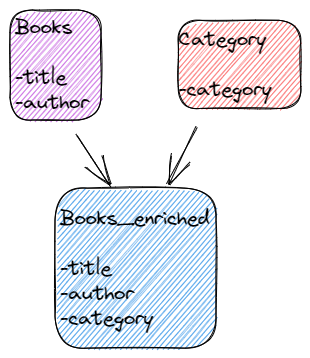
En la aplicación procesaremos eventos que vienen desde el tópico "books". Se trata de enriquecer estos en el tópico "book_enriched" buscando su "category":
books + category = books_enriched
Configuración
A continuación mencionaremos las partes importantes del proyecto Spring Boot. Siempre tenemos disponible todo el código fuente en el link github.
https://github.com/leonardotorresaltez/custom-metrics-demo
Paso 1
Elegir el stack de versiones para evitar bugs relacionados con exportar las métricas de Kafka Streams en Spring Boot.
Para ello veremos la matriz de compatibilidad spring-kafka
pom.xml :
. . .
<org.springframework.boot.version>2.7.5</org.springframework.boot.version>
<org.springframework.spring-kafka.version>2.9.3</org.springframework.spring-kafka.version>
<org.apache.kafka-clients.version>3.2.3</org.apache.kafka-clients.version>
. . .
Paso 2
Construir un endpoint que nos muestre todas las métricas out-the-box "KafkaMetric" ya incluidas en el producto. Esto nos servirá para verificar que se exportan todas.
public class UtilRestController {
. . .
@GetMapping("/showRawKafkaStreamMetrics")
public String showMetrics() {
var kafkaStreams = streamsBuilderFactoryBean.getKafkaStreams();
if (Objects.isNull(kafkaStreams)) {
return "No metrics logged. KafkaStreams is null";
}
Map<MetricName, ? extends Metric> metrics = kafkaStreams.metrics();
log.info("KakfaStream metrics: {}", metrics);
for (Map.Entry<MetricName,?> entry : metrics.entrySet())
{
org.apache.kafka.common.metrics.KafkaMetric valueInside = (org.apache.kafka.common.metrics.KafkaMetric)entry.getValue();
log.info("Item: " + entry.getKey() + ", Value: " + valueInside.metricValue());
}
return "Raw Kafka metrics logged";
}
}
Paso 3
Configurar propiedades
Para elegir qué métricas capturar, usar la propiedad "metrics.recording.level"
spring:
kafka:
bootstrap-servers: localhost:9092
streams:
application-id: "streams.alertascolacaja.miseventos.v3"
bootstrap-servers: "localhost:9092"
properties:
state.dir: state-dir
metrics.recording.level: "TRACE"
properties:
schema.registry.url: http://localhost:8081
auto.offset.reset: latest
auto.register.schemas: true
default.deserialization.exception.handler: org.apache.kafka.streams.errors.LogAndContinueExceptionHandler
default.production.exception.handler: org.apache.kafka.streams.errors.DefaultProductionExceptionHandler
default.key.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
default.value.serde: io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde
En la versión de spring-kafka que utilizamos, todas estas métricas están ya disponibles en el endpoint micrometer de spring-kafka /actuator/metrics, con excepción de las métricas que no tiene valor numérico, como por ejemplo la que imprime la topología en formato texto.
El valor del propiedad metrics.recoding.level debe estar en TRACE para poder capturar las métricas end to end. No se recomienda usar el valor TRACE en entornos productivos por el footprint que introducen.
Paso 4 (opcional)
Construir un endpoint para mostrar la topología en formato texto. Una de las formas es consultar una métrica que ya la contiene.
public class TopologyEndPoint {
. . .
@ReadOperation
public String topology() {
var kafkaStreams = streamsBuilderFactoryBean.getKafkaStreams();
if (Objects.isNull(kafkaStreams)) {
return "No metrics logged. KafkaStreams is null";
}
Map<MetricName, ? extends Metric> metrics = kafkaStreams.metrics();
for (Map.Entry<MetricName,?> entry : metrics.entrySet())
{
org.apache.kafka.common.metrics.KafkaMetric valueInside = (org.apache.kafka.common.metrics.KafkaMetric)entry.getValue();
if ( entry.getKey().name().equals("topology-description")) {
Object value = valueInside.metricValue();
log.info("Topology: {}", value.toString());
return value.toString();
}
}
return "not found";
}
}
Paso 5
Codificar métricas custom
Usamos la clase BookEnrichedProcessor para enriquecer los datos de Book añadiendo datos de Category y devolviendo un BookEnriched.
Es en la clase BookEnrichedProcessor donde configuramos y usamos la métrica custom.
Hay que configurar sensor y añadirle una métrica en metodo init:
public class BookEnrichedProcessor implements Processor<String, BookEnriched, Void, Void> {
. . .
@Override
public void init(final ProcessorContext<Void, Void> processorContext) {
categoryStateStore = processorContext.getStateStore(applicationConfig.getStateStoreCategoryTopic());
//1- contenedor para todas las metricas
StreamsMetrics streamsMetrics = processorContext.metrics();
//2- añadir los tags, son opcionales
Map<String, String> metricTags = new HashMap<String, String>();
metricTags.put("metricTagKey", "metricsTagVal");
//3- se crea la metrica
MetricName metricName = new MetricName("my-process-time", "stream-processor-node-metrics","description",metricTags);
//4- se añade la metrica al contenedor de metricas
sensorStartTs = streamsMetrics.addSensor("start_ts", Sensor.RecordingLevel.INFO);
//5- configurar el sensor, en este caso guardar valores promedio
sensorStartTs.add(metricName, new Avg());
}
}
registrar un valor en la métrica en el método process:
long iniTime = System.currentTimeMillis();
//process . . .
long elapsedTime = System.currentTimeMillis() - iniTime;
System.out.println("ElapsedTime - " + elapsedTime);
sensorStartTs.record(Long.valueOf(elapsedTime).doubleValue());
Paso 6
Verificar que las métricas custom y end2end son exportadas.
Verificar las métricas con el endpoint custom creado de Kafka Metrics:
- http://localhost:8080/showRawKafkaStreamMetrics
Verificar las métricas con el endpoint out-of-the-box micrometer Spring Boot:
- http://localhost:8080/actuator/metrics
- http://localhost:8080/actuator/prometheus
Ejemplo de output:
# HELP kafka_stream_processor_node_my_process_time description
# TYPE kafka_stream_processor_node_my_process_time gauge
kafka_stream_processor_node_my_process_time{kafka_version="3.2.3",metricTagKey="metricsTagVal",spring_id="defaultKafkaStreamsBuilder",} 0.2
Paso 7 (opcional)
Exportar las métricas a prometheus y grafana para una mejor visualización y alertado.
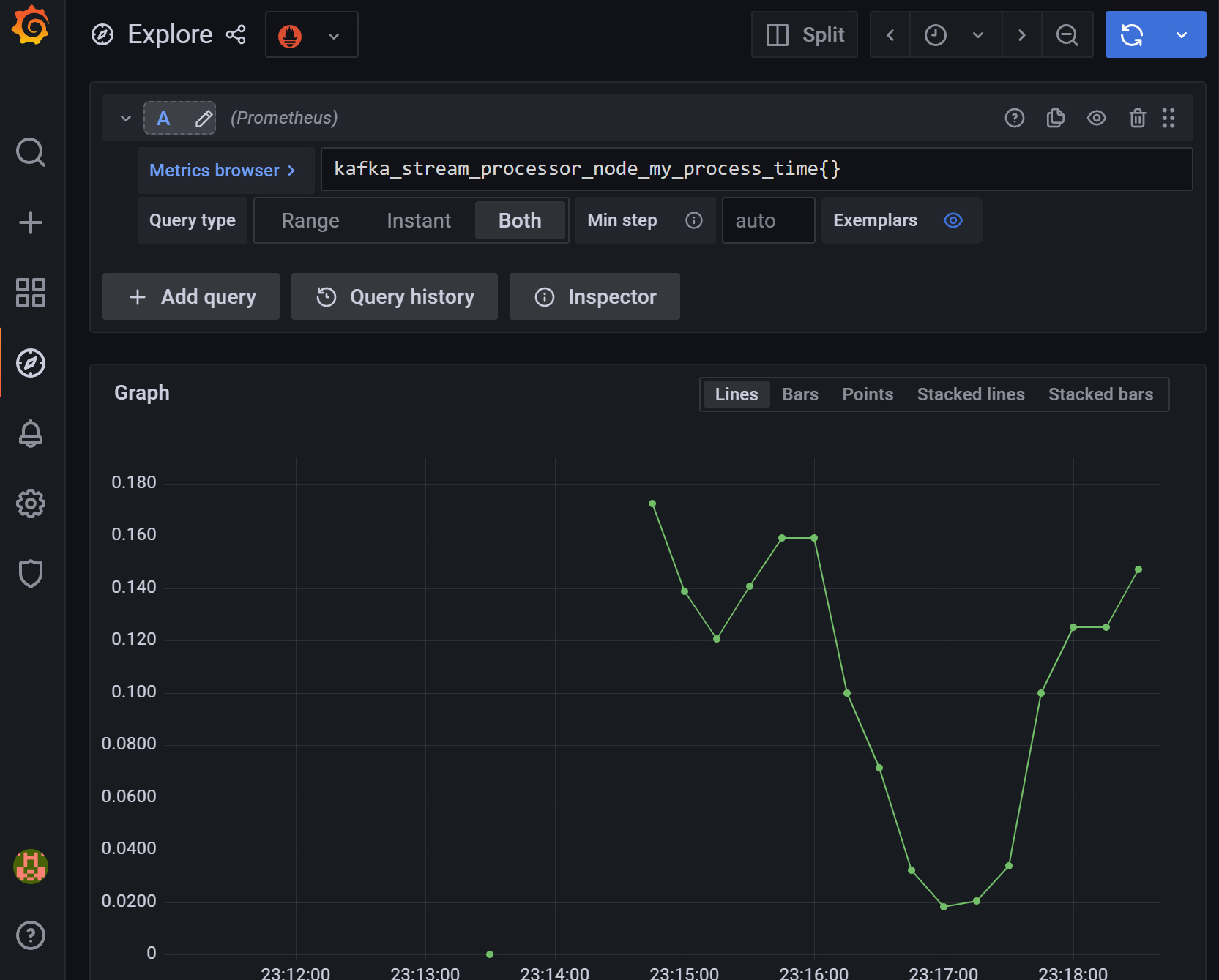
Conclusión
Kafka Streams proporciona un marco de programación fácil de usar para crear aplicación de flujo de datos que se procesan en tiempo real.
Usar las métricas custom y out-of-the-box es necesario para tener la solución final monitoreada y con alertas. A diferencia de métricas más simples de una aplicación típica que procesa mensajes por un endpoint http, en kafka es más complejo, ya que se procesan los datos por bloque (parámetro max.poll.records) y se transforman, agregan, filtran en diferentos nodos (subtopologias). Por esto es importante usar el api de Kafka Metrics.