Machine Learning con Elasticsearch
Introducción
El objetivo principal de utilizar la herramienta de machine learning que nos ofrece el stack de elastic, es aprovechar al máximo el valor de la información que indexamos. Hasta ahora podíamos obtener visualizaciones con búsquedas en tiempo real o realizar agregaciones de datos, pero ahora con machine learning podemos afrontar un comportamiento más particular y tener visualizaciones más específicas, utilizando técnicas de aprendizaje.
Por lo general, el objetivo que se persigue es la detección de anomalías en series temporales de información. El sistema va a ir aprendiendo cuál es su comportamiento normal, formando un patrón. Cuando existen valores que se desvían de este comportamiento, se informará como una anomalía. Esto se realiza construyendo un modelo probabilístico conforme el sistema va aprendiendo. La idea de utilizar un sistema probabilístico frente a un sistema de reglas estáticas, reducirá el número de falsos positivos
Casos de uso
Existen multitud de posibles casos de uso del módulo de machine learning de elastic, pero algunos de los más genéricos podrían ser:
- Códigos de Respuesta – Analizar códigos de respuesta para detectar errores en los servicios
- Métricas de CPU – Analizar sobrecarga de uso de la CPU
- Procesos sospechosos – Detectar endpoints inusuales en un servidor
- Análisis de acceso – Ver volúmenes de accesos de usuario a una aplicación
- DNS spoofing – Evitar ataques de suplantación de información mediante DNS
¿Y qué beneficios podemos obtener con el uso de este módulo?
Por ejemplo, podemos destacar los plannings de capacidad (realizar una estimación del espacio ocupado/libre), la sobrecarga de sistemas (estimar puntos críticos de sobrecarga del sistema) y el estudio de tiempos de respuesta elevados (analizar las métricas de respuesta para detectar problemas con servicios).
Alertas
Cuando se configura un job de machine learning existe la posibilidad de realizar exploración del tipo de anomalía que se produce. Los diferentes tipos son baja, warning y crítica, dependiendo de la comparación temporal con el aprendizaje adquirido en anteriores ejecuciones.
Uno de los puntos fuertes del análisis de anomalías son las alertas. Se pueden configurar alertas de correo electrónico (además de invocación a webhooks y otras múltiples integraciones con terceros) cuando ocurra un tipo concreto de anomalía en el job y de esta forma poder actuar de manera inmediata ante cualquier tipo de problema.
Previsiones
A partir de la versión 6.1 de x-pack se ha añadido la nueva funcionalidad de previsiones bajo demanda. Se puede utilizar para prever cual va a ser el comportamiento en los próximos días. Elasticsearch almacena estas predicciones en el mismo índice del job de machine learning para compararlas posteriormente con el comportamiento real.
Machine Learning sobre Logs de un sistema productivo real
A continuación, vamos a detallar el estudio para un cliente de dos casos en sus sistemas productivos.
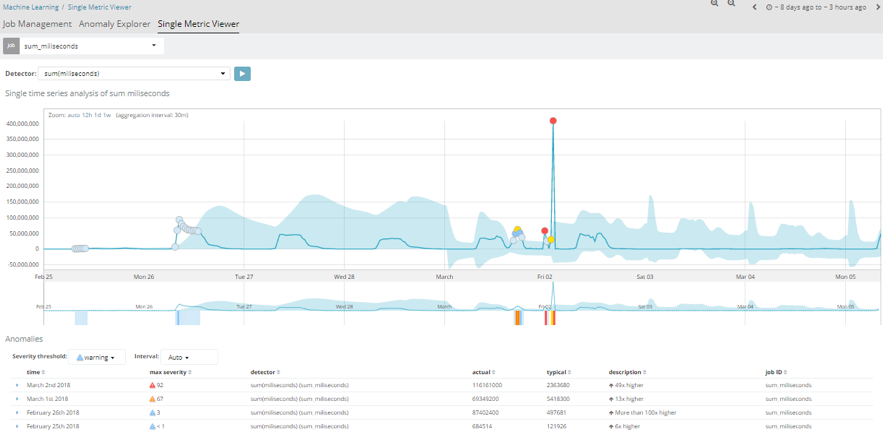
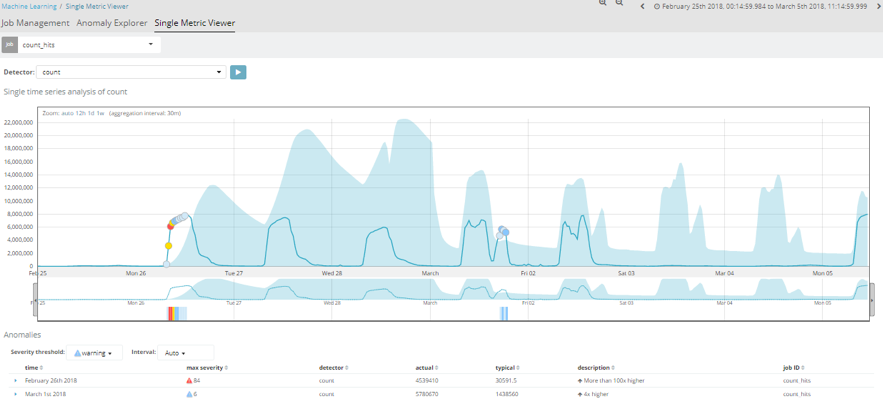
El primero de ellos sería un análisis del número de Hits por espacio temporal. Este job básicamente representa una gráfica con el número de documentos que se almacenan en un índice. El análisis se realiza con un intervalo de 15 minutos y como podemos observar representa un patrón más o menos homogéneo.
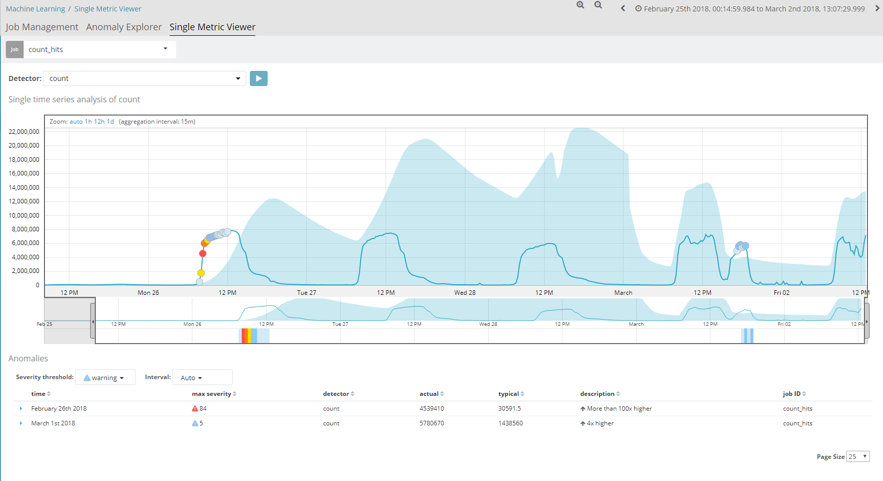
Inicialmente, cuando se crea un job de machine learning, la primera de las iteraciones siempre resulta poco coherente, ya que no tiene información anterior con la que comparar los valores que empieza a recibir.
La banda azul de la imagen representa la tendencia que tiene el patrón de este job. Conforme avanza en el tiempo, y el job va teniendo más información, podemos observar como esta franja termina por acercarse bastante a los valores reales, ya que el aprendizaje está ya muy avanzado.
Otro de los casos de estudio es el tiempo de respuesta en milisegundos de las diferentes aplicaciones. En este caso, podemos observar que también se cumple un patrón homogéneo como ocurría en el primero de los ejemplos. Pero si nos fijamos, el día 2 de Febrero se produjeron varias alertas críticas. Esto fue debido a que ese día se habilitó la una nueva aplicación en la empresa, y empezaron a caer servicios a causa de las avalanchas de peticiones sobre esta nueva aplicación. Por tanto, el tiempo en milisegundos de cada petición se incrementó notablemente saliéndose de sus valores habituales.
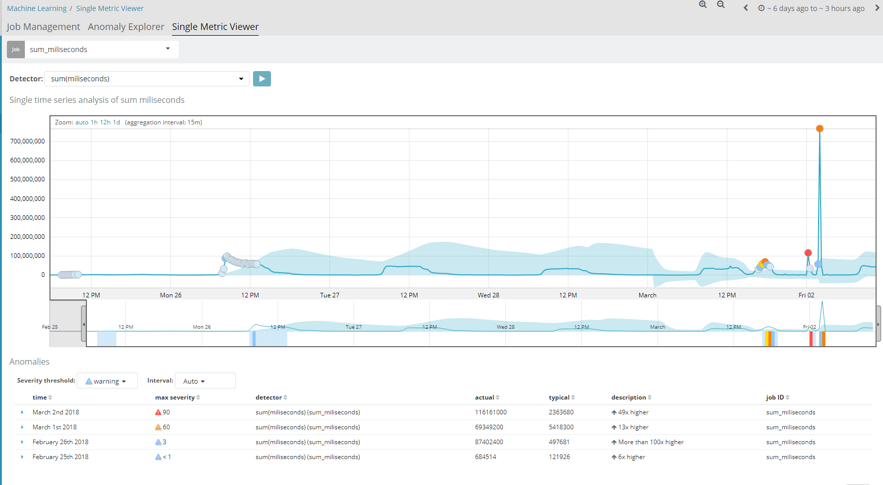
Este es un claro ejemplo de que haciendo uso de este módulo podemos saber de inmediato (ayudándonos con alertas) cuando se está produciendo un comportamiento anómalo en nuestro sistema y solucionarlo lo más rápido posible.